
Published Nov 20, 2019
How Artificial Intelligence Is Getting Us Closer to Star Trek’s Universal Translators
Current automatic translation can’t compete with the 24th century’s, but it’s made astronomical progress in the past decade.
StarTrek.com
Universal translators make everything possible in the Star Trek series: First Contacts, interspecies relationships, human characters crying to Guinan over their synthale. In fact, they work so seamlessly that the viewer tends not to notice they exist until they encounter the occasional problem, as they do in DS9’s “Sanctuary” or Voyager’s “Nothing Human.”
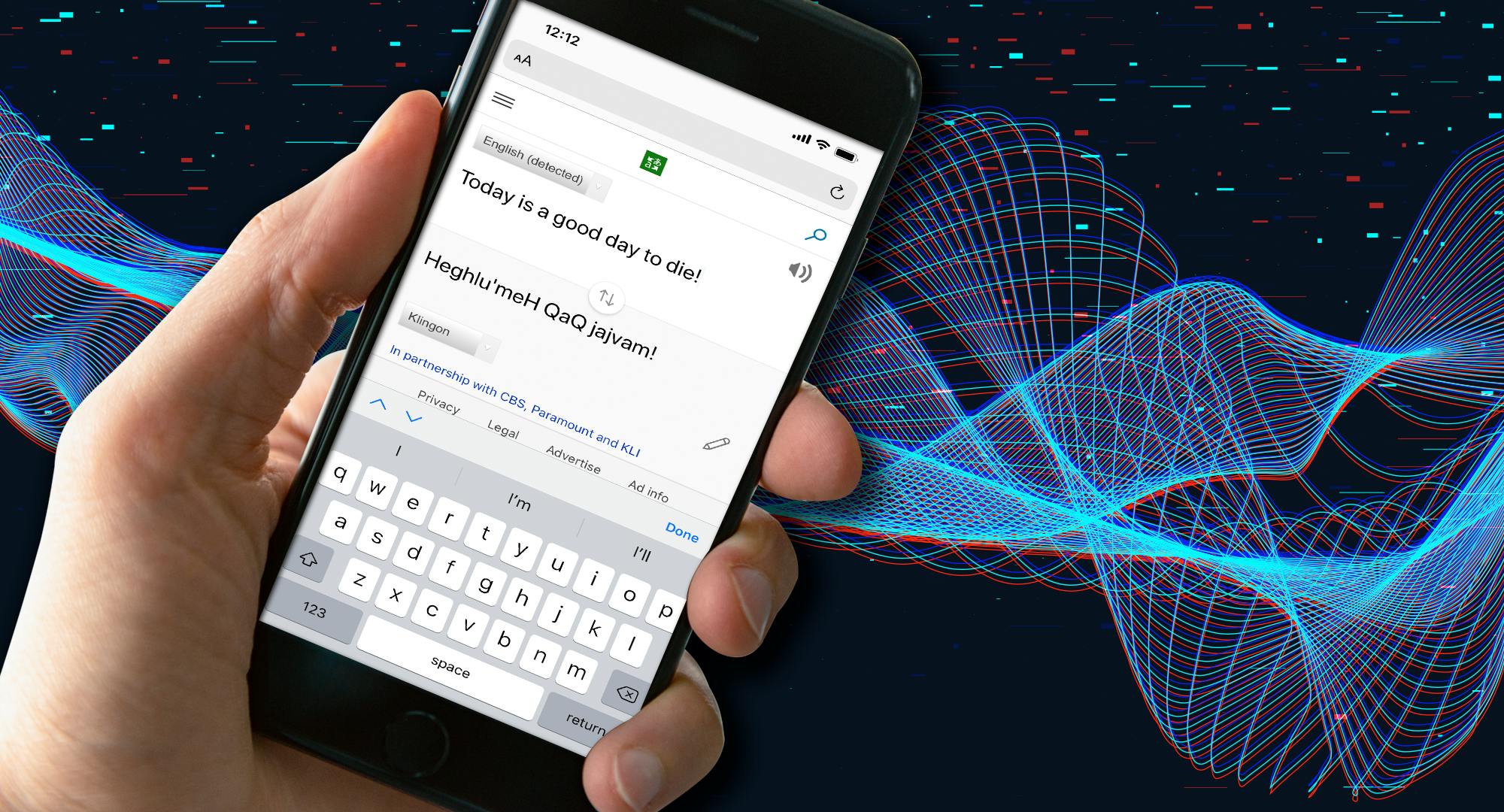
By comparison, machine translation as we know it in the early 21st century is messy and incomplete. Everyone who’s used Google Translate or seen automatically translated text on social media knows that it’s not yet at Starfleet’s level.
But machine translation, a sub-field of artificial intelligence research, has made great leaps in the past decade. So have speech recognition and speech synthesis, the fields of AI that respectively understand human speech and create human-like speech from a computer. Those are the technologies that underlie voice-activated personal assistants like Apple’s Siri or Amazon’s Alexa. Put them together with machine translation—as Google, Microsoft and a handful of startups have—and you have something like a universal translator.
“Over the last maybe 10, 15 years, we've gone from a couple of demos to actually having something that ends up being on either the phone or on the desktop,” says Alan Black, a professor at Carnegie Mellon University’s Language Technologies Institute.

StarTrek.com
The first of these may have been Jibbigo, a smartphone app developed by Alex Waibel, Black’s colleague at Carnegie Mellon, and sold to Facebook in 2013. Waibel, who also teaches at the Karlsruhe Institute of Technology in his native Germany, says a technology like the universal translator has been a dream of his ever since he was a graduate student at MIT in the late 1970s. In fact, his work on the problem led to a visit from William Shatner in 1999, when Shatner and a coauthor were researching a book on how real science was catching up to science fiction.
Things have improved in the 20 years since then, but even the best machine translation tool is still a long way from a Starfleet universal translator. For starters, they tend to offer only a handful of the Earth’s thousands of languages. That’s partly because only certain languages are considered commercially viable; but it’s also because of how the systems work. Typically, they use speech recognition to understand the spoken words and put them into text, then put that through a machine translation system. The output is then converted to sound through speech synthesis.
The bottleneck is with the machine translation. To make sense of their inputs, these systems need huge amounts of data on each language—100 million words of text—so that they can match words that translate to one another. For some language pairs, that’s easy to get. For example, the Canadian government translates huge amounts of documents between French and English, creating “parallel texts” that say the same thing in each language.
But some languages don’t have much data available, and some language pairs don’t have much parallel text, perhaps because their speakers don’t have much direct contact. Some of those problems are solved by going through a third language, but many languages simply aren’t included in current machine translation systems.
For the same reason, it’s currently impossible to achieve the universal translator’s ability to pick up new languages immediately, as it does in numerous first contact episodes from The Next Generation, Deep Space Nine and Voyager. (The technology is less well settled on Enterprise, often requiring help from exolinguist Hoshi Sato.) Even with 24th-century processing speeds, the computer would still need a way to map that data onto a known language.

StarTrek.com
“Is it analyzing a very large corpus of parallel text where it’s got some known language and the target language? Then maybe,” says Emily M. Bender, a computational linguistics professor at the University of Washington. “Is it analyzing a very large corpus of just the text of the target language? Then hopeless.”
Unlike the Trek universal translator, which is depicted as instantaneous, most current technologies need to wait at least until the end of a statement before starting their translation. There may be technical reasons for that, but differences between the sentence structures can also be the culprit. For example, if the original language puts the verb at the end of the sentence a simultaneous translation to English (which puts verbs in the middle) is challenging. Black notes that human interpreters have tricks for handling this, including anticipating what the speaker is likely to say, but computers aren’t as good at that.
Another largely unsolved problem is accounting for the aspects of communication that rely more on tone of voice or delivery than actual words. This involves not just emphasis—i.e., I want this one—but emotion, humor and sarcasm, in which tone of voice alone conveys that the speaker means the opposite of what was said.
“Those are some of the things that may get lost in translation, so to speak, and they are still open research questions,” says Shri Narayanan, professor and Niki and C.L. Max Nikias Chair in Engineering at the University of Southern California.
And then there are cultural differences, which Narayanan says are also difficult to capture with a whole lot of data. But they’re important, because what’s funny—or what’s rude, or what’s awkward—is highly dependent on culture.
If you don’t believe this, imagine asking a drunk Klingon any question at all. Or you can try navigating life in Japan as a native English speaker. Black, who has lived in Japan, says it’s considered so rude in Japan to directly say “no” that Japanese speakers will instead say things like “it’s difficult,” even when the discussion is about which bus to take.
There’s more hope for other aspects of spoken language that currently elude machine translation technology. One of these is metaphors, which formed the basis of an entire episode of The Next Generation. In “Darmok” (S5E2), the universal translator picks up the words of the Tamarians just fine. But because they speak in metaphors, it takes an entire episode for Captain Picard to understand what the Tamarian captain is saying.

StarTrek.com
You don’t need to leave the planet to have this problem; American English speakers could easily be confused by a literal translation of the Cantonese “add oil,” meaning “keep at it.” Bender says current technologies can sometimes handle common metaphors, if they occur in the training data along with an explanation or a corresponding metaphor in the other language. If not, however, they’re likely to get something literal that might be confusing.
One way to solve that is to teach the computers what the words and phrases they’re translating actually mean to a human listener. Currently, machine translation simply matches patterns. That can cause big problems, ranging from misgendering people to actively wrong translations, but it can be hard to spot if the translation looks sensible and fluent otherwise. Because of that, Bender believes machine translation systems should have a built-in way to double-check accuracy.
“In the Star Trek universe... if they get something through the translator, they 100% believe that they know what the initial message was,” she says. “But it's absolutely not something that we should be doing in our actual universe with the current or any foreseeable versions of this technology.”
And so, as it turns out, the Universal Translator is yet another touchstone of Star Trek’s optimistic version of the future that we must continue to strive towards.
Lorelei Laird (she/her) is a freelance writer specializing in the law and other difficult topics that need clear explanations. She lives in Los Angeles with her family, and you can find her at www.wordofthelaird.com.